In complex IoT deployments, raw sensor data is only the starting point. A solar inverter might report that it’s generating 25 kW, but on its own, that number tells you very little. Is it performing well? To answer that, you need more information: What is the inverter’s DC capacity? What is the current solar irradiance? What is its expected performance curve?

This process of enriching raw data with descriptive and operational information is called data contextualization. It transforms isolated readings into actionable intelligence, bridging the gap between physical assets and their digital representation.

Why Data Contextualization Matters for Asset Operations
Imagine a newly commissioned solar power plant managed by a team of contractors. They possess invaluable hands-on knowledge—such as which inverters were challenging to troubleshoot, which panel strings receive afternoon shade, and the unique quirks of each piece of equipment. This tribal knowledge—critical insights held by a few experts—drives the project’s initial success.
Once the project transitions to your maintenance team, much of this expertise disappears. Knowledge remains locked with the experts or scattered across disconnected spreadsheets and diagrams. The problem isn’t that the knowledge is lost; it’s that it becomes operationally invisible—unavailable at the time and place it’s needed most, alongside real-time sensor data.
This is where data contextualization comes in. It doesn’t replace expert knowledge; it preserves it and makes it universally accessible—transforming fragile, siloed insights into structured, permanent metadata. By onboarding each inverter with details like capacity, model, and installation specifics, you create a durable digital representation. This ensures your team and AI systems have the context needed to manage assets effectively throughout their lifecycle.
Learn in this blog post, how your AI agent can utilize IoT data and context in order to make better recommendations and take action.
What Are the Building Blocks of Data Contextualization?
A robust digital twin or AI model relies on a solid foundation. These building blocks help systematically capture, structure, and validate operational knowledge.
Creating Your Asset Hierarchy (The “Digital Blueprint”)
Even with 10,000 perfectly defined data points—you just have a long list. You can’t ask questions like, “What’s the total generation of Substation 2?” or “Which inverters are on the north-facing string?”. You have visibility, but no structure.
The asset hierarchy is the digital blueprint that structures your assets based on their real-world physical or logical relationships. It defines how you group and connect data, turning what would otherwise be a flat stream of information into a queryable, navigable model that reflects how your operations actually function.
Example Hierarchy:
Solar Plant Düsseldorf
├── Substation 1
│ ├── Inverter 101
│ │ ├── INV-101\_T\_amb (Temperature)
│ │ └── INV-101\_P\_act (Active Power)
│ └── Inverter 102
│ ├── INV-102\_T\_amb
│ └── INV-102\_P\_act
├── Substation 2
│ └── \[Similar structure\]
└── Monitoring Station
└── \[Environmental sensors\]
Now you can query assets logically. You can “roll up” the active power from all inverters under Substation 1 to get its total output, transforming a flat list of sensors into a virtual model of your plant.
Adding Static Asset Context: The “Rich Context” Layer
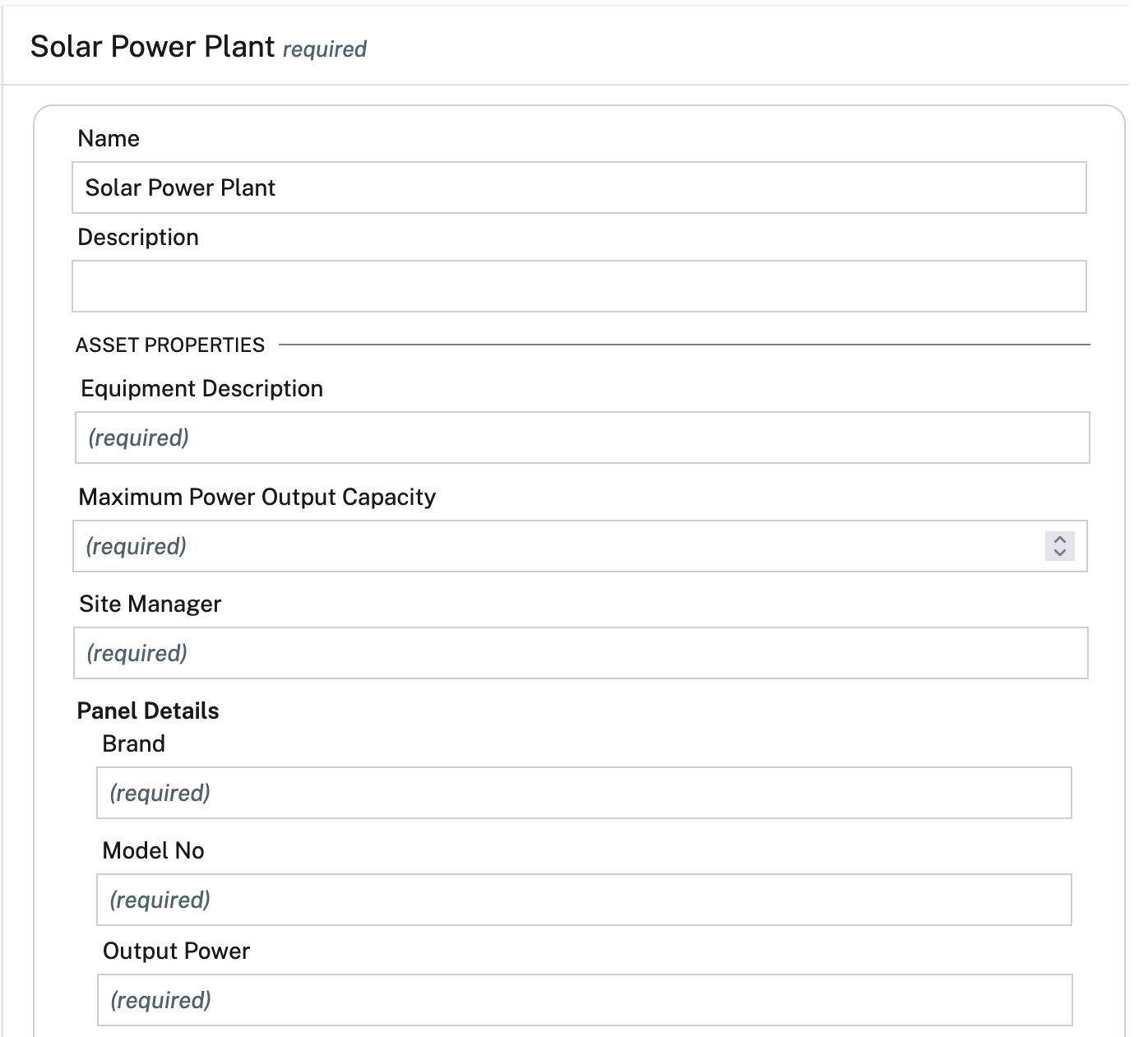
The hierarchy is the skeleton; metadata adds substance. Attach rich, static information—installation details, maintenance logs, and engineering diagrams—to each asset in your hierarchy, creating a single source of truth.
- Metadata for “Inverter 101”:
- Model: SunGrow SG-25CX
- DC Capacity: 25 kW
- Install Date: 2023-04-10
- Installer: Contractor XYZ
- Warranty Expiry: 2033-04-10
- Last Maintenance: 2024-09-15
- User Manual: URL
When a 25 kW reading comes in, the operator sees the full picture: "Inverter 101 (SunGrow SG-25CX, 25 kW capacity) is reporting 25 kW, which is 100% of its rated capacity. Last maintained 1 month ago. "
Data Point Context
Sensors often report values using tags like INV-1_T_amb or 20-41A-T1, which can be difficult to interpret. These codes introduce semantic ambiguity—for example, does T_amb refer to ambient temperature or transformer temperature?
That’s where a metadata model comes in. It serves as a central registry that defines each datapoint before it’s used. With a metadata model in place, everyone—from engineers to data scientists—can interpret data consistently, build accurate dashboards, and train AI models with shared, reliable definitions.
Think of it as the semantic layer that makes data universally understandable.
Example:
- INV-1_T_amb becomes :
- Name: Inverter 1 Ambient Temperature
- Unit: °C
- Min: -30°C
- Max: 60°C
- Data Type: Number
This ensures the data is usable for anyone, not just the original integrator. When building dashboards or AI models, everyone shares the same understanding of “temperature.”
This is the foundation. Only after taking these steps can you truly scale.
Implementing Contextualization in Practice
Connecting devices is only the first step. Once they are onboarded, teams face the long-term challenge of systematically capturing, structuring, validating, and governing the contextual layers that make data actionable.
Many organizations begin with familiar tools such as spreadsheets, ad-hoc scripts, or internal wikis. This “context” (asset locations, model numbers, maintenance notes, etc.) often lives in documents maintained manually by a few senior engineers. While this may work for a small pilot, it becomes a bottleneck as you scale.
The data is not disconnected from sensor inputs, but rather from the broader IT landscape that needs this context—it exists primarily in the heads and files of human experts. As a result, maintenance engineers must switch between systems to diagnose a single issue, wasting valuable time during outages. Because this context is static and inaccessible to systems, any automation must be manually driven by human experts. If the context were structured and machine-readable, AI could generate and trigger workflows automatically and attach relevant context to field service tickets—significantly speeding up diagnosis and resolution.
To overcome these challenges, you need a system designed to manage and govern this contextual layer. It must enable teams—from operational experts to maintenance engineers—to collaboratively define, enrich, and maintain context throughout the asset lifecycle. Critically, it should offer an intuitive, easy-to-use interface that fits naturally into the maintenance engineer’s workflow, minimizing friction and driving high adoption. The system should also integrate with foundational platforms such as ERP and asset management tools, and provide APIs to share contextualized data with other enterprise systems.
To make this less abstract, let’s look at how adding context works in practice with Cumulocity.
An intuitive, visual UI is essential, it makes it easier for solution architects, operational experts, installers, and maintenance teams to collaboratively define and maintain asset context. Their input is critical for capturing accurate metadata, relationships, and operational information.
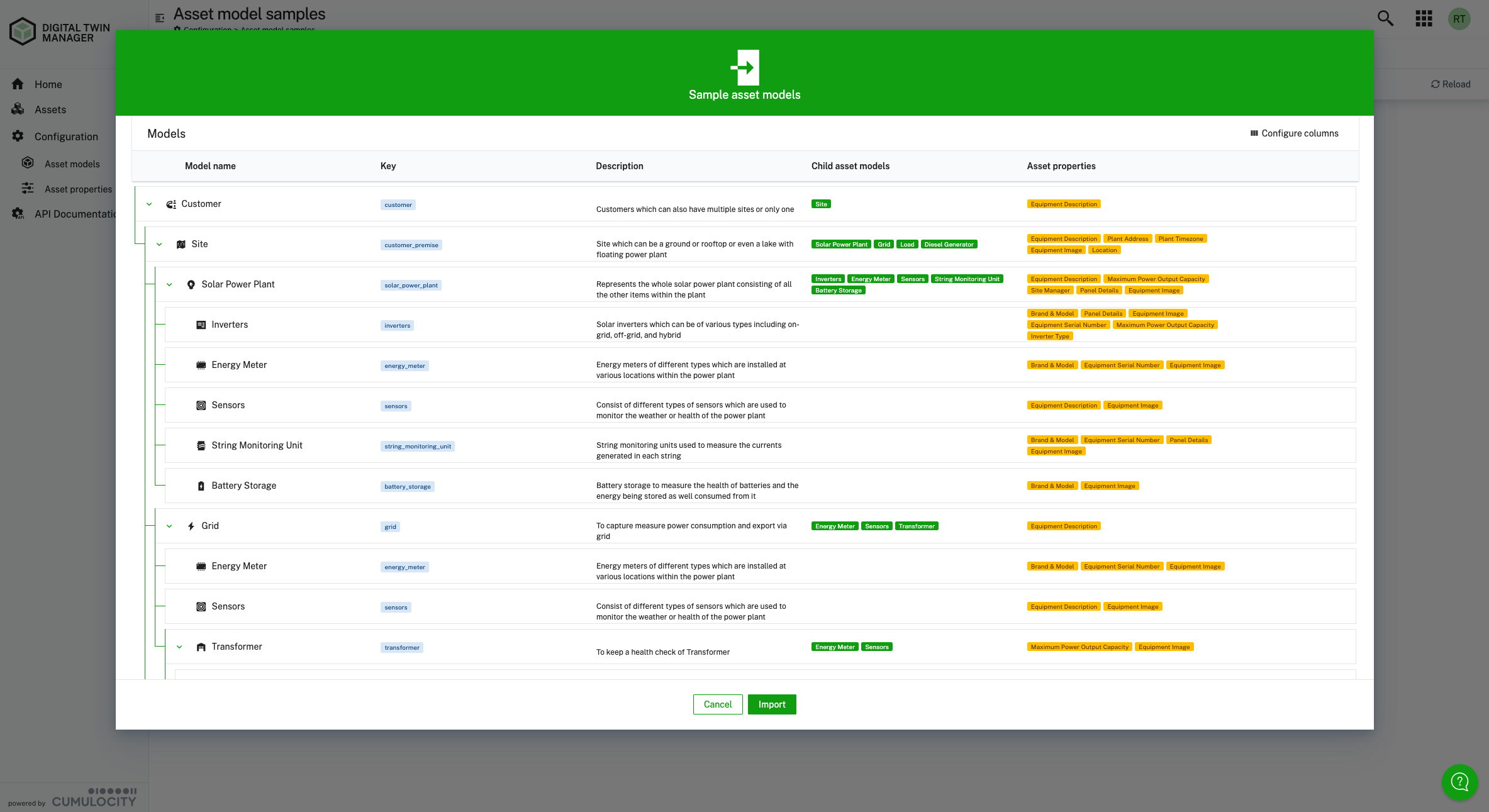
Reusable Models : You can design and enforce reusable asset models to ensure consistency across deployments. The platform should also allow importing existing hierarchies or metadata from ERP or asset-management systems, enabling teams to build on established data sources while refining and evolving the digital model.
Integrated APIs for Automation: APIs support both importing foundational context and sharing enriched, contextualized data with other enterprise systems. For example, when a real-time rule triggers a “Critical” alarm, an API can automatically push the asset’s model, location, and maintenance history into an FSM system to create a work order.
Ultimately, contextualization transforms raw device data into actionable intelligence. With intuitive tools, collaborative input, and seamless integrations, organizations can build a living digital model that evolves with operations—delivering accurate insights, enabling faster decisions, and driving more efficient workflows across the enterprise.
Learn in this guide, how you can build your context-aware AI agent with Cumulocity to provide assistance or automate your workflows.
Next Step: How to Model Your Assets at Scale
Data contextualization lays the foundation, turning raw telemetry into rich, reliable intelligence for digital twins and AI. To achieve fleet-wide value, your data structure must be scalable, flexible, and designed to serve diverse business objectives—from predictive maintenance to energy optimization.
In our next article, we’ll explore how to use these building blocks to design a scalable asset modeling framework for managing thousands—or even millions—of industrial assets, including the metadata schemas that enabled one operator to achieve 40% faster incident response. This transforms your digital blueprint into a robust, fleet-wide foundation for all intelligent IoT solutions.